Where would we be without 'em?
Our experience of the Internet is often facilitated through the use of search engines and search directories. Before they were invented, people’s Net experiences were confined to plowing through sites they already knew of in the hopes of finding a useful link, or finding what they wanted through word of mouth.
As author Paul Gilster puts it in Digital Literacy "How could the world beat a path to your door when the path was uncharted, uncatalogued, and could be discovered only serendipitously?".
This may have been adequate in the early days of the Internet, but as the Net continued to grow exponentially, it became necessary to develop a means of locating desired content.
At first search services were quite rudimentary, but in the course of a few years they have grown quite sophisticated.
Not to mention popular. Search services are now among the most frequented sites on the Web with millions of hits every day.
Even though there is a difference between search engines and search directories (although less so every day), I will adopt the common usage and call all of them search engines.
Archie and Veronica
The history of search engines seems to be the story of university student projects evolving into commercial enterprises and revolutionizing the field as they went. Certainly, that is the story of Archie, one of the first attempts at organizing information on the Net. Created in 1990 by Alan Emtage, a McGill University student, Archie archived what at the time was the most popular repository of Internet files, Anonymous FTP sites.
Archie is short for "Archives" but the programmer had to conform to UNIX standards of short names.
What Archie did for FTP sites Veronica did for Gopherspace. Veronica was created in 1993 at the University of Nevada. Jughead was a similar Gopherspace index.
Robots
Archie and Veronica were for the most part indexed manually. The first real search engine in the sense of a completely automated indexing system is MIT student Matthew Gray’s World Wide Web Wanderer.
The Wanderer robot was intended to track the growth of the Web counting only web servers initially. Soon after its launch it captured URLs as well. This list formed the first database of websites, called Wandex.
Robots at this time were quite controversial. For one, they occupied a lot of network bandwidth and they would index sites so rapidly it was not uncommon for the robots to crash servers.
In the Glossary for Information Retrieval Scott Weiss describes a robot as:
[a] program that scans the web looking for URLs. It is started at a particular web page, and then accesses all the links from it. In this manner, it traverses the graph formed by the WWW. It can record information about those servers for the creation of an index or search facility.
Most search engines are created using robots. The problem with them is, if not written properly, they can make a large number of hits on a server in a short space of time, causing the system’s performance to decay.
The First Web Directory
In response to the problems with automated indexing of the Web, Martjin Koster in Oct. 1993 created Aliweb, which stands for Archie Like Indexing of the Web. This was the first attempt to create a directory for just the Web.
Instead of a robot, webmasters submit a file with their URL and their own description of it. This allowed for a more accurate, detailed listing.
Unfortunately, the application file was difficult to fill out so many websites were never listed with Aliweb,
Spiders
By December 1993, three more robots, now known as spiders, were on the scene: JumpStation, World Wide Web Worm (developed by Oliver McBryan in 1994, bought out by Goto.com in 1998) and the Repository-Based Software Engineering (RBSE) spider.
RBSE made the important step of listing the results based on relevancy to the keyword. This was crucial. Prior to that, the results were in no particular order and finding the right location could require plowing through hundreds of listings.
Excite was launched in February 1993 by Stanford students and was then called Architext. It introduced concept based searching. This was a complicated procedure that utilized statistical word relationships, such as synonyms. This turned up results that might have been missed by other engines if the exact keyword was not entered.
WebCrawler, which was launched in April 20, 1994, was developed by Brian Pinkerton of the University of Washington.
It added a further degree of accuracy by indexing the entire text of webpages. Other search engines only indexed the URL and titles, which meant that some pertinent keywords might not be indexed. This also greatly improved the relevancy rankings of their results.
As an interesting aside, WebCrawler offers an insightful service, WebCrawler Search Voyeur, that allows you to view what people are searching as they enter their queries. You can even stop it and see the results.
Search Directories
There was still the problem that searchers had to know what they were looking for, which as I can attest, is often not the case. The first browsable Web directory was EINet Galaxy, now known as Tradewave Galaxy, which went online January 1994. It made good use of categories and subcategories and so on.
Users could narrow their search until presumably they found something that caught their eye.
It still exists today and offers users the opportunity to help coordinate directories, becoming an active participant in cataloging the Internet in their field perfected the search directory, however.
Yahoo! grew out of two Stanford University students, David Filo’s and Jerry Yang’s, webpages with their favourite links (such pages were quite popular back then).
Started in April 1994 as a way to keep track of their personal interests, Yahoo soon became too popular for the university server.
Yahoo’s user-friendly interface and easy to understand directories have made it the most used search directory. But because everything is reviewed and indexed by people, their database is relatively small, accounting for approximately 1% of webpages.
The Big-Guns
When a search fails on Yahoo it automatically defaults to AltaVista’s search.
AltaVista was late onto the scene in December 1995, but made up for it in scope.
AltaVista was not only big, but also fast. It was the first to adopt natural language queries as well as Boolean search techniques. And to aid in this, it was the first to offer "Tips" for good searching prominently on the site. These advances made for unparalleled accuracy and accessibility.
But AltaVista had competition: HotBot, introduced May 20, 1996 by Paul Gauthier and Eric Brewer at Berkeley. Powered by the Inktomi search engine, it was initially licensed to Wired Magazine website. It has occasionally boasted it can index the entire Web.
Indexing 10 million pages per day, it is the most powerful search engine.
Meta-Engines
The next important step in search engines is the rise of meta-engines. Essentially they don’t offer anything new. They just simultaneously compile search results from various different search engines. Then list the results according to the collective relevancy.
The first meta-engine was MetaCrawler released in 1995. Now called Go2net.com it was developed in 1995 by Eric Selburg, a Masters student at the University of Washington .
Skewing Relevancy
Prior to Direct Hit, launched in the summer of 1998, there were two types of search engines: author controlled services, such as AltaVista and Excite, in which the results are ranked by keyword relevancy and editor-controlled, such as directories like Yahoo and LookSmart, in which people manually decide on placement.
Direct Hit, as inventor Gary Culliss relates: "represents a third kind of search, one that's user-controlled, because search rankings are dependent on the choices made by other users." As users choose to go to a listed link, they keep track of that data and use the collected hit-ratio to calculate the relevancy. So the more people go to the site from Direct Hit the higher it will appear on their results.
which runs as a research project at Stanford University since late 1997, also attempts to improve relevancy rankings. Google uses PageRank, which basically monitors how many sites link to a given page. The more sites and the more important the sites that link to a given site the higher the ranking in the result list.
It does give a slight advantage to .gov and .edu domains. Basically, it is trying to do what Yahoo does but without the need for costly human indexing.
Is This Fair?
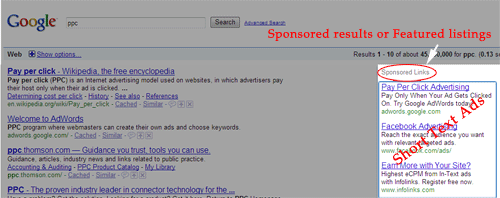
Another way of fixing relevancy rankings is by selling prominent placement as Goto.com does. Founded by idealab and Bill Gross, this practice caused quite a controversy. Apparently, there was some doubt as to the actual relevancy of its paid prominent listings. Goto insists that their clients must adhere to a "strict policy" of relevance to the corresponding keywords.
Their corporate site defends its approach:
"In other search engines, there is no cost to spamming or word stuffing or other tricks that advertisers use to increase their placement within search results. When you get conscious decisions involved, and you associate a cost to them, you get better results... GoTo uses a revolutionary new principle for ranking search results by allowing advertisers to bid for consumer attention, and lets the market place determine the rankings and relevance."
For the right amount of money you can ensure your site is placed #1.
Check out the words that are still "unbidden".
Look similar?
That's for the courts to decide now. Goto.com has filed suit February 1999, against the Disney owned Go Network.
Finding a niche
As search engines try to index the entire Web, some search engines have found their niche by narrowing their field to a specific subject or geographical region. Argos was the first to offer a Limited Area Search Engine. Launching October 3, 1996, they index only sites dealing with medieval and ancient topics. A panel decides on whether a site is suitable for inclusion.
Their mandate was to combat such problems as this example (from their site):
"At the time of this writing, a search for "Plato" on the Internet search engine, Infoseek, returned 1,506 responses. Of the first ten of these, only five had anything to do with the Plato that lived in ancient Greece, and one of these was a popular piece on the lost city of Atlantis. The other five entries dealt with such things as a home automation system called, PLATO(tm) for Windows, and another PLATO(r), an interactive software package for the classroom. Elsewhere near the top of the Infoseek list was an ale that went by the name of Plato, a guide to business opportunities in Ireland, and even a novel called the "Lizard of Oz."
Such specializing has also proven effective for MathSearch, Canada.com, and hundreds of others.
Ask Jeeves' niche is making search engines more searchable for the average user. (Who really knows Boolean anyway?) Founded in 1996, but not really well-used until recently, Ask Jeeves has a more human approach. Refining natural language queries so that users can ask normal questions. For example, "Whatever happened to Upper Volta?".
When a question is answered it matches similar queries it has already received and offers these as its results. This is supposed to help guide users to the desired location when they might not know themselves how else to find it.
The Next Generation
There is no denying that these sites are among the most popular websites. They mark the daily entry point into the Web experience.
Search engines are trying to offer more and to be more. Whether it is Northern Light’s private fee-based online library or Yahoo offering free email and content (news, horoscopes, etc.). Search engines are continuing to evolve.
We are seeing the sophistication of the spiders in finding and indexing sites, the increase in user-friendly searching techniques and interface, the expanding of databases and the improved relevancy of results from the database.
(Now if they could just make some money doing it, as most of the companies mentioned continue to operate at a loss.)
As I learned while researching this topic, search engines may open up the door to the World Wide Web, but not without some difficulty. Searching is far from easy or perfect.
As the Web continues to grow rapidly, the need for better search engines only increases.